01 / Why I built thisEvery bad sprint I've shipped started with a spec I thought was done.
After seven years at Amazon writing PRDs for Trust & Safety, I got tired of the same pattern: engineering reads the spec, nods, builds it, and halfway through discovers a missing metric, a mis-scoped edge case, or a stakeholder we forgot to loop in. Costly. Avoidable. Structural.
The best PM tradition for catching this is the "red-team review" — pull in a peer who'll try to break your spec before engineering does. The problem: peers are expensive, slow, and often too polite.
02 / The systemFive specialists, one orchestrator, one readiness score.
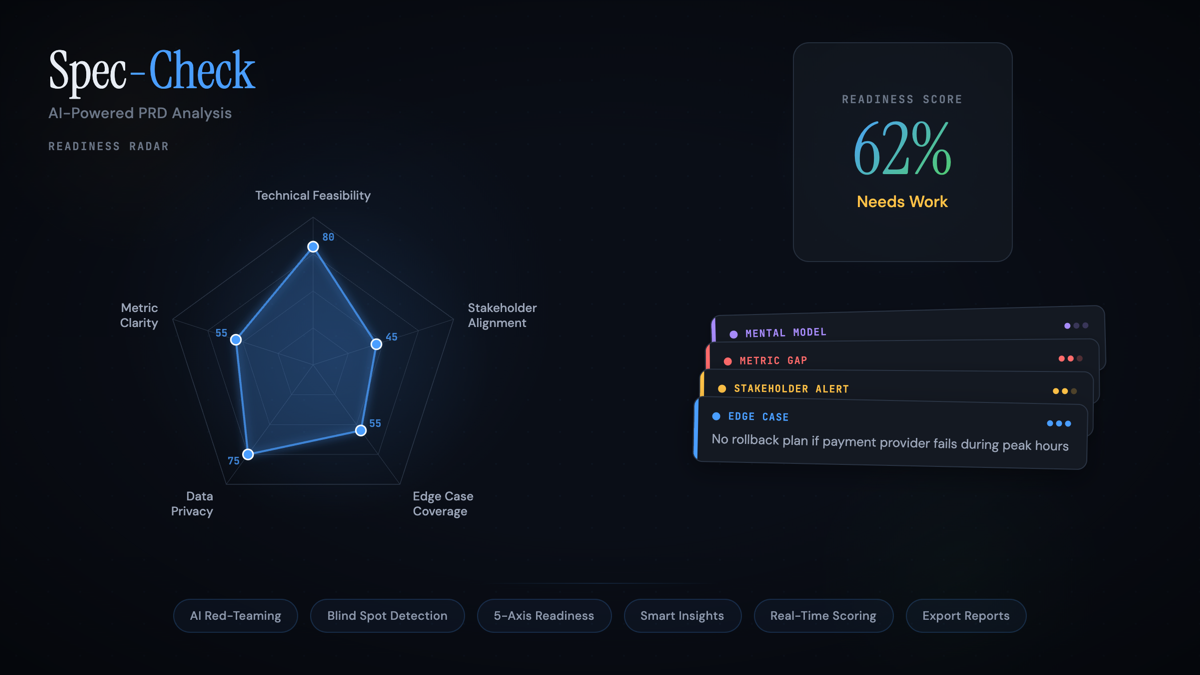
Spec-Check runs your PRD through five parallel agents, each with a single sharp mandate. The orchestrator collects their findings, deduplicates, ranks severity, and returns a unified Readiness Score from 0–100 along with actionable gaps.
- Technical Feasibility — flags architecture assumptions, integration risk, unbounded compute, and hand-wave language like "scalable" or "simply."
- Stakeholder Alignment — detects missing owners, ambiguous decision rights, and language that papers over unresolved disagreements.
- Metric Clarity — checks that success metrics are measurable, attributable, and tied to user behavior (not vanity counters).
- Edge Case Coverage — synthesizes failure-mode tests: what breaks at zero, at scale, under partial outages, across regions.
- Data Privacy — scans for PII handling, consent paths, retention, and regional compliance gaps (GDPR, CPRA).
03 / A quick demo
Here's the core output pattern — radar across the five axes, a composite Readiness Score, and the top issues ranked by severity. Click a scenario to see how the chart responds.
04 / Design decisions
Specialist > generalist. I initially tried a single agent with a long rubric. It produced mush — every axis scored 60-ish, no sharp findings. Splitting into five single-mandate agents dropped variance and surfaced findings sharp enough to act on. The orchestrator became thinner, not thicker.
A score, not a verdict. Readiness Score is a diagnostic, not a gatekeeper. It's ambiguous by design — 62% means "go, but with these three things fixed first." A binary pass/fail would have been easier to build and worse to use.
Severity bands, not stars. Findings ship in four bands — Mental Model, Metric Gap, Stakeholder Alert, Edge Case — because that's how engineers triage. The findings got more useful when I stopped being clever with severity names.
05 / Outcomes
Using Spec-Check on my own work caught three shippable-looking PRDs with critical gaps before they ever hit engineering — one of which would have cost a week of rework.
06 / What this project taught me
- Orchestrated multi-agent systems are genuinely better than single-agent ones for judgment tasks — not because models are stronger, but because mandates stay sharper.
- The UX around agent output is 70% of the product. Nobody trusts a number without severity, evidence, and a path to act on it.
- Agentic tools are at their best when they review human work, not when they replace it.